

下载好数据后,开始干活
目前我们有2020年09月到2021年10月每个月的ndvi均值tif,当然由于云的影响,很多地方是有空洞的,下面记录一下处理过程
首先哨兵2的ndvi数据是四张不同范围的图,先对其做个镶嵌拼成一幅图
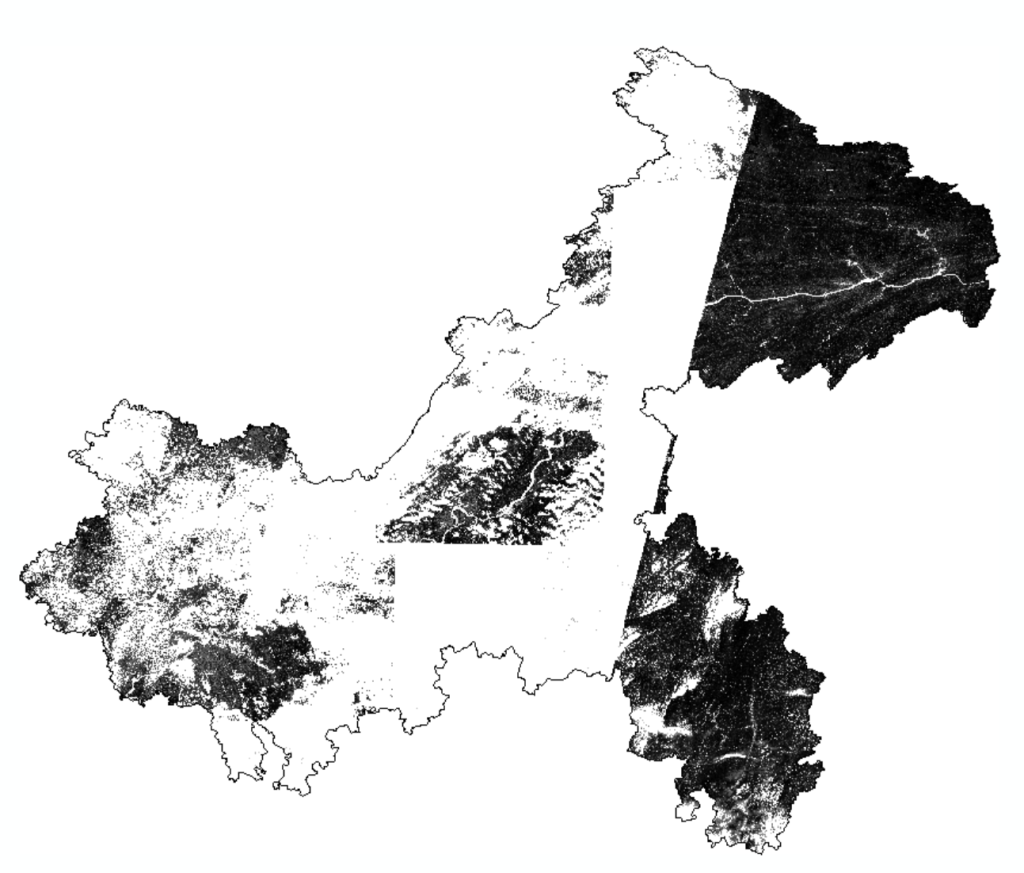
发现有很多地方都没有数据,没事我们还有landsat数据

landsat数据还没经过裁剪,先通过掩膜提取进行裁剪
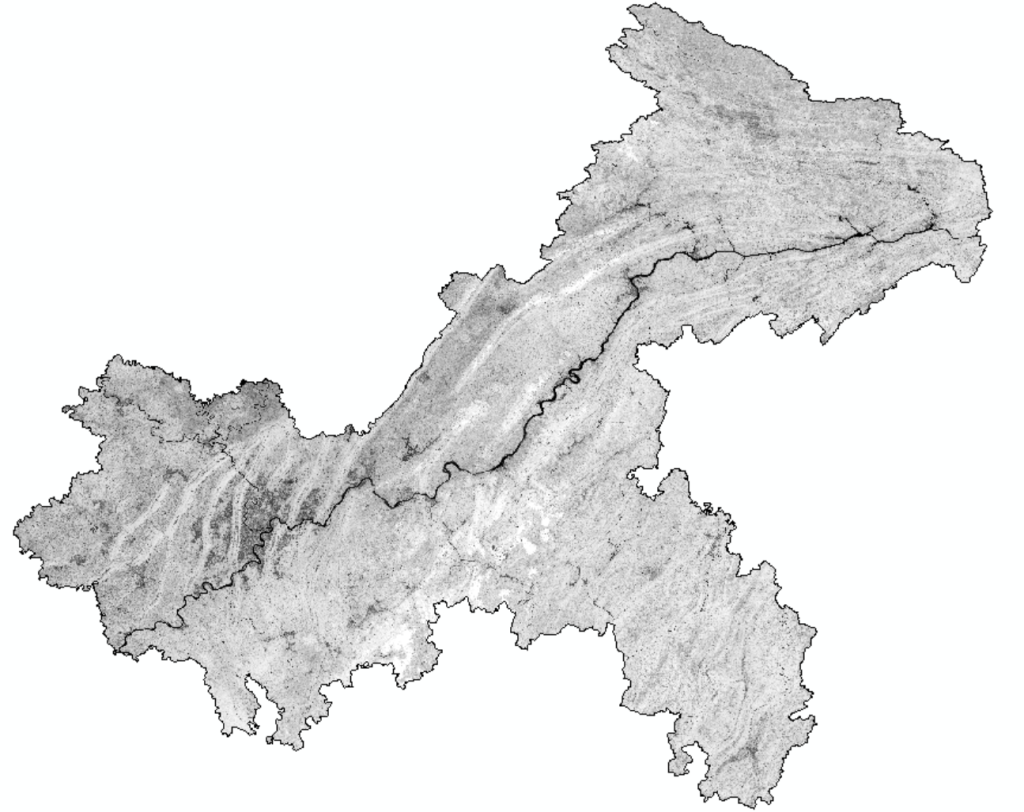
之后进行镶嵌,要注意镶嵌时取值的顺序,保证哨兵2优先于landsat,然后还要设置像元大小,保持和哨兵2一致
镶嵌后还是有少量空洞没有数据,接着用高分数据再进行填充,可惜高分数据只经过预处理,还是以县域为单位存储,并且要手动计算ndvi
首先写一个脚本将高分数据调整存储组织形式
def list_dir(path = None):
date=["202009","202010","202011","202012","202101","202102","202103","202104","202105","202106","202107","202108","202109","202110"]
dir_list = os.listdir(path)
for cur_file in dir_list:
cur_path = os.path.join(path, cur_file)
if os.path.isfile(cur_path):
print (cur_path)
if(cur_path[-3:]=="tif"):
if(cur_path[-10:-4] in date):
to_path ="E:/ndvi_prj/gf/" + cur_path[-10:-4]
shutil.move(cur_path,to_path)
print("move to"+to_path)
if(cur_path[-3:]=="ovr"):
if(cur_path[-14:-8] in date):
to_path = "E:/ndvi_prj/gf/" + cur_path[-14:-8]
shutil.move(cur_path,to_path)
print("move to"+to_path)
elif os.path.isdir(cur_path):
print("{0} : is dir!".format(cur_path))
list_dir(cur_path) # 递归子目录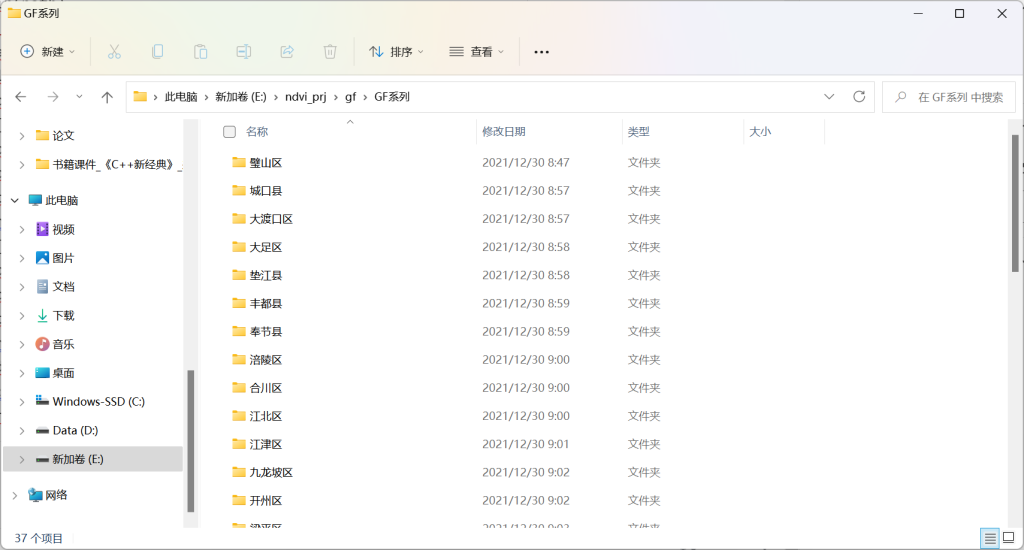
一次导入该月所有的图像,镶嵌选最大值,因为这个数据的背景值是RGB(0,0,0)而不是NaN,之后用云掩膜进行抠出。用重庆市shp和云掩膜交集取反,然后掩膜提取
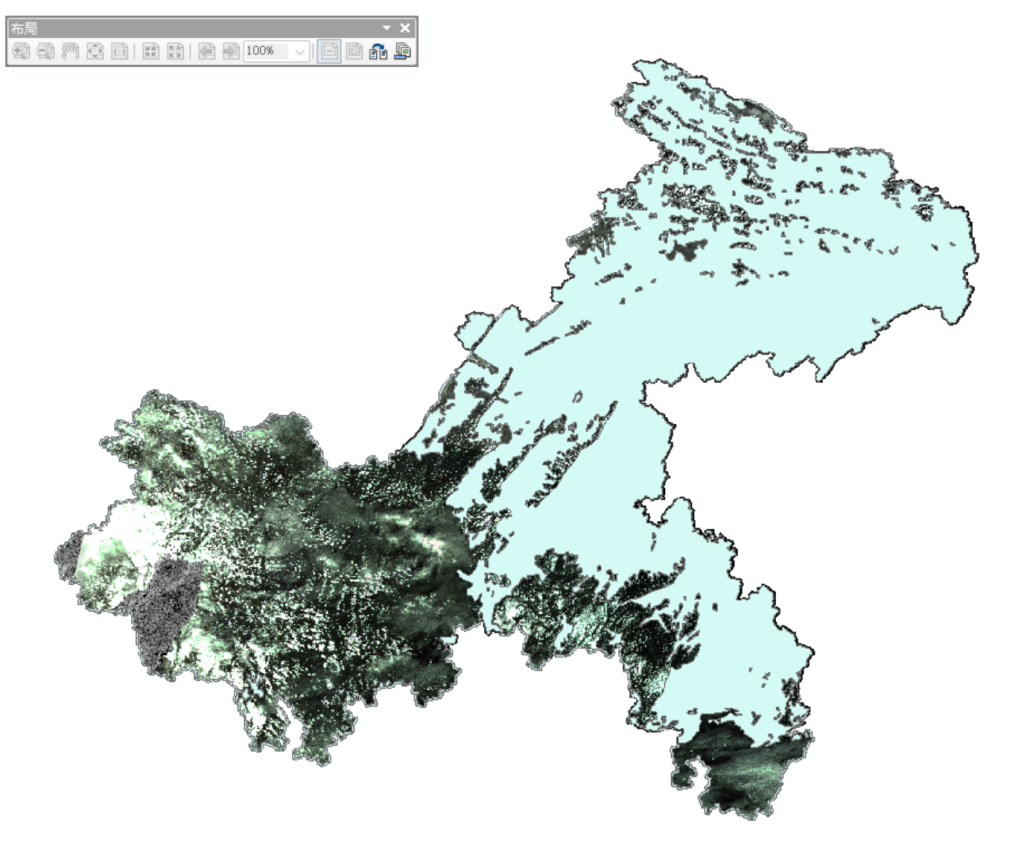
按掩膜提取,注意掩膜必须是shp而不是要素,否则会出错

>>> import os
import time
import arcpy
from arcpy import env
def zonal(raster, shp):
attri_table = "zonalstat"
arcpy.gp.ZonalStatisticsAsTable_sa(shp, "FID", raster, attri_table, "NODATA", "MEAN")
arcpy.JoinField_management(shp,"FID", attri_table, "FID")
if __name__ == "__main__":
time1 = time.time()
ndvi_ras = 'E:/ndvi_prj/ndvi_2000/202010.tif'
shp = 'E:/ndvi_prj/500101/500101.shp'
temp_path = 'E:/ndvi_prj//temp/'
arcpy.CheckOutExtension('Spatial')
arcpy.env.overwriteOutput = True
env.workspace = temp_path
zonal(ndvi_ras, shp)
time2 = time.time()
print((time2-time1) / 3600.0)arcpy进行分区统计并字段连接
但是速度还是太慢,于是换成提取中心点值进行赋值
流程是1要素转点2多值赋值到点3字段连接4删除多于字段
在操作过程中发现删除多余字段时速度极慢且出错,折腾半天原来是shp的属性表(dbf文件)过大,导致溢出。因而将删除多于字段放在第一步来做。QGIS的保留字段可以生成新的shp,速度比arcgis删除字段快很多
Comments NOTHING