

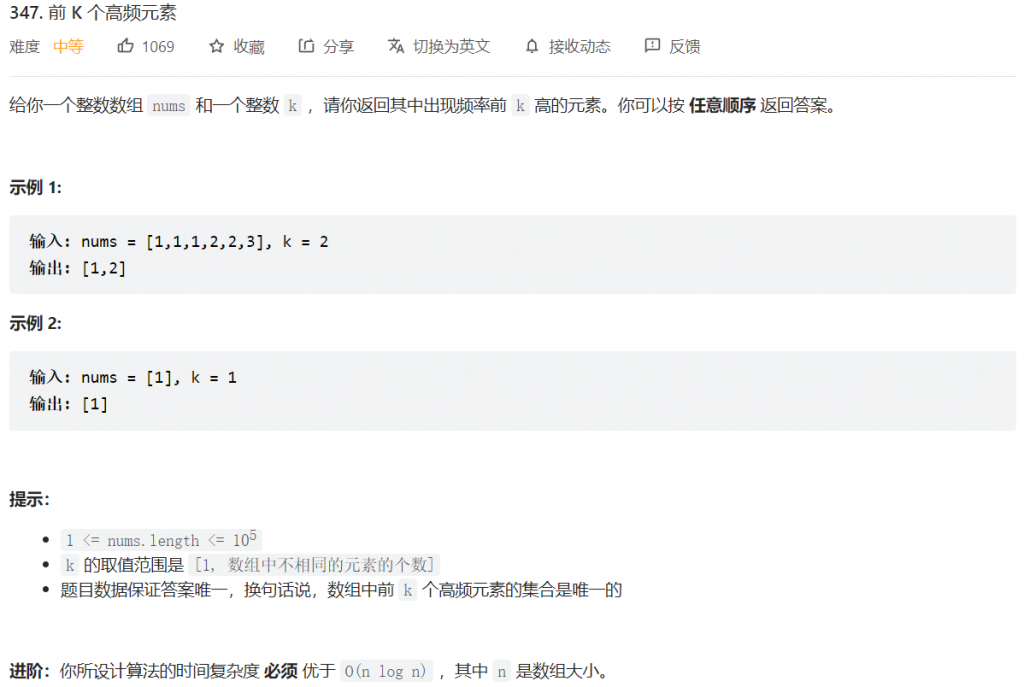
题目并不难,首先遍历一次数组,用哈希表计数,然后对次数排序,返回前k个值就行。
记录一下unordered_map的用法方便以后查阅。
首先unordered_map与map的区别在于是否排序,前者实现是哈希表,后者实现是红黑树,其他函数基本相同,都是用pair作为存储单元。
pair结构相对简单,就是两个值组成一个变量。
pair<T1, T2> p1; //创建一个空的pair对象(使用默认构造),它的两个元素分别是T1和T2类型,采用值初始化。
pair<T1, T2> p1(v1, v2); //创建一个pair对象,它的两个元素分别是T1和T2类型,其中first成员初始化为v1,second成员初始化为v2。
make_pair(v1, v2); // 以v1和v2的值创建一个新的pair对象,其元素类型分别是v1和v2的类型。
p1 < p2; // 两个pair对象间的小于运算,其定义遵循字典次序:如 p1.first < p2.first 或者 !(p2.first < p1.first) && (p1.second < p2.second) 则返回true。
p1 == p2; // 如果两个对象的first和second依次相等,则这两个对象相等;该运算使用元素的==操作符。
p1.first; // 返回对象p1中名为first的公有数据成员
p1.second; // 返回对象p1中名为second的公有数据成员unordered_map详细用法见详细介绍C++STL:unordered_map - 朤尧 - 博客园 (cnblogs.com)
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int,int> times;
for(auto i: nums){
if(times.find(i)==times.end())
times.insert({i,1});
else
times[i]++;
}
vector<pair<int,int>> tmp;
for(auto i:times)
tmp.push_back(i);
sort(tmp.begin(), tmp.end(), [=](std::pair<int, int>& a, std::pair<int, int>& b) { return a.second > b.second; });
vector<int> answer;
for(int i=0;i<k;i++){
answer.push_back(tmp[i].first);
}
return answer;
}
};注意到对unordered_map排序可以用vector的sort,并自定义比较函数。可以直接写在sort参数里,也可以在外部写好,将函数名传进去。
这里[=]lambda函数的变量引用方式,详见C++之Lambda表达式 - 季末的天堂 - 博客园 (cnblogs.com)
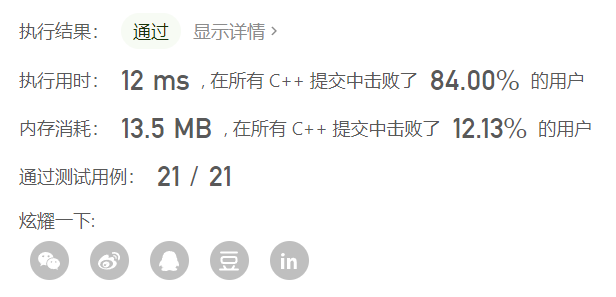
这样写问题不大,但效率浪费在我们只要前k个值,并不需要对整个数组排序,这种只要排序前k个值的情况很适合用堆来实现,这题是正序就用大顶堆。
大顶堆之前的文章也写过实现方式,但没写stl库里的priority_queue用法,因此这里补上。
常规的priority_queue的定义如下
Type 就是数据类型,Container 就是容器类型(Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector),Functional 就是比较的方式,当需要用自定义的数据类型时才需要传入这三个参数,使用基本数据类型时,只需要传入数据类型,默认是大顶堆
//升序队列
priority_queue <int,vector<int>,greater<int> > q;
//降序队列
priority_queue <int,vector<int>,less<int> >q;
//greater和less是std实现的两个仿函数(就是使一个类的使用看上去像一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了)
但是这题我们需要将堆的元素改为pair,但使用pair的优先队列的比较函数是先比较first再比较second,因此还需要重写比较函数。参考自定义类型的优先队列方法定义符合要求的priority_queue
#include <iostream>
#include <queue>
using namespace std;
//方法1
struct tmp1 //运算符重载<
{
int x;
tmp1(int a) {x = a;}
bool operator<(const tmp1& a) const
{
return x < a.x; //大顶堆
}
};
//方法2
struct tmp2 //重写仿函数
{
bool operator() (tmp1 a, tmp1 b)
{
return a.x < b.x; //大顶堆
}
};
int main()
{
tmp1 a(1);
tmp1 b(2);
tmp1 c(3);
priority_queue<tmp1> d;
d.push(b);
d.push(c);
d.push(a);
while (!d.empty())
{
cout << d.top().x << '\n';
d.pop();
}
cout << endl;
priority_queue<tmp1, vector<tmp1>, tmp2> f;
f.push(c);
f.push(b);
f.push(a);
while (!f.empty())
{
cout << f.top().x << '\n';
f.pop();
}
}
将解法进行修改
class Solution {
public:
static bool cmp(pair<int,int> &a,pair<int,int> &b){return a.second>b.second;}//static限制函数作用范围
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int,int> times;
for(auto i: nums){
if(times.find(i)==times.end())
times.insert({i,1});
else
times[i]++;
}
priority_queue<pair<int,int>,vector<pair<int,int>>,decltype(&cmp)> temp(cmp);
for(auto i:times){
if(temp.size()<k)
temp.push(i);
else{
if(i.second>temp.top().second){
temp.pop();
temp.push(i);
}
}
}
vector<int> answer;
while(!temp.empty()){
answer.push_back(temp.top().first);
temp.pop();
}
return answer;
}
};
至于仿函数,decltype等搞懂后在更吧
还是写个struct易懂一些
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
//1.map记录元素出现的次数
unordered_map<int,int>map;//两个int分别是元素和出现的次数
for(auto& c:nums){
map[c]++;
}
//2.利用优先队列,将出现次数排序
//自定义优先队列的比较方式,小顶堆
struct myComparison{
bool operator()(pair<int,int>&p1,pair<int,int>&p2){
return p1.second>p2.second;//小顶堆是大于号
}
};
//创建优先队列
priority_queue<pair<int,int>,vector<pair<int,int>>,myComparison> q;
//遍历map中的元素
//1.管他是啥,先入队列,队列会自己排序将他放在合适的位置
//2.若队列元素个数超过k,则将栈顶元素出栈(栈顶元素一定是最小的那个)
for(auto& a:map){
q.push(a);
if(q.size()>k){
q.pop();
}
}
//将结果导出
vector<int>res;
while(!q.empty()){
res.emplace_back(q.top().first);
q.pop();
}
return res;
}
};
Comments NOTHING