

paddle官方上一章教程介绍了卷积神经网络的一些基本概念和数学原理,这一章就以图像分类任务入手介绍各种经典卷积网络结构
官方教程链接:图像分类
首先是LeNet,这个网络结构相对比较简单,和之前手写数字的网络结构相似。
# 导入需要的包
import paddle
import numpy as np
from paddle.nn import Conv2D, MaxPool2D, Linear
## 组网
import paddle.nn.functional as F
# 定义 LeNet 网络结构
class LeNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(LeNet, self).__init__()
# 创建卷积和池化层块,
# 创建第1个卷积层
self.conv1 = Conv2D(in_channels=1, out_channels=6, kernel_size=5)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
# # 创建第2个卷积层;尺寸的逻辑:池化层未改变通道数;输出通道等于卷积核的数量,该层共6*16个卷积核
self.conv2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
# 创建第3个卷积层
self.conv3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4)
# 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W]
# 输入size是[32,32],经过三次卷积和两次池化之后,C*H*W等于120
self.fc1 = Linear(in_features=120, out_features=64)
# 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数
self.fc2 = Linear(in_features=64, out_features=num_classes)
# 网络的前向计算过程
def forward(self, x):
x = self.conv1(x)
# 每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化
x = F.sigmoid(x)
x = self.max_pool1(x)
x = F.sigmoid(x)
x = self.conv2(x)
x = self.max_pool2(x)
x = self.conv3(x)
# 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W]
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = F.sigmoid(x)
x = self.fc2(x)
return x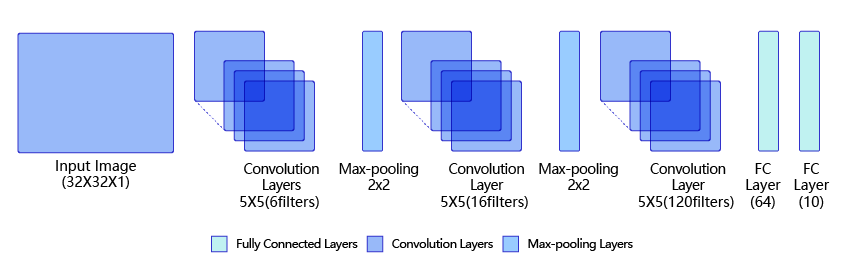
在学习别人提出的经典网络结构时,我们应该自己想想每一层输出的矩阵shape是什么,并且用随机数作为输入,查看经过LeNet-5的每一层作用之后,输出数据的形状来验证自己的计算是否正确。
如果输入是28×28的图像,第一层卷积是5×5的卷积核,共6个通道,步长默认是1,那么卷积后得到的结果就是24×24×6通道
之后2×2池化,步长2,输出尺寸减半,通道不变,结果是12×12×6
第三层同样的卷积,同样5×5,输入通道6,输出通道16(输入通道要注意和上一层的输出结果通道数一致),步长还是1,输出结果就是8×8×16
第四层一样的池化,尺寸减半,输出4×4×16
第五层,最后一次卷积,转为120通道,输出1×1×120。注意这里因为输入是28×28,所以最后一层卷积的kernel是4×4的尺寸。要求最后卷积完是1×1的size好后面进行线性计算。如果输入图像是32成32,也就是和上面示意图一样,那么每层的size就变成了【28×28×6->14×14×6->10×10×16->5×5×16】那么最后一层卷积就要把卷积核(kernel)的size改成5×5。
之后两层线性化就是把先把1×1×120的输出降维成120的数组,然后线性计算第一次到64,第二次到10(num_class,类别数)
当然上面都没算batch-size,batch-size直接放前面就行,没有影响。
# 输入数据形状是 [N, 1, H, W]
# 这里用np.random创建一个随机数组作为输入数据
x = np.random.randn(*[3,1,28,28])
x = x.astype('float32')
# 创建LeNet类的实例,指定模型名称和分类的类别数目
m = LeNet(num_classes=10)
# 通过调用LeNet从基类继承的sublayers()函数,
# 查看LeNet中所包含的子层
print(m.sublayers())
x = paddle.to_tensor(x)
for item in m.sublayers():
# item是LeNet类中的一个子层
# 查看经过子层之后的输出数据形状
try:
x = item(x)
except:
x = paddle.reshape(x, [x.shape[0], -1])
x = item(x)
if len(item.parameters())==2:
# 查看卷积和全连接层的数据和参数的形状,
# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数b
print(item.full_name(), x.shape, item.parameters()[0].shape, item.parameters()[1].shape)
else:
# 池化层没有参数
print(item.full_name(), x.shape)[Conv2D(1, 6, kernel_size=[5, 5], data_format=NCHW), MaxPool2D(kernel_size=2, stride=2, padding=0), Conv2D(6, 16, kernel_size=[5, 5], data_format=NCHW), MaxPool2D(kernel_size=2, stride=2, padding=0), Conv2D(16, 120, kernel_size=[4, 4], data_format=NCHW), Linear(in_features=120, out_features=64, dtype=float32), Linear(in_features=64, out_features=10, dtype=float32)] conv2d_6 [3, 6, 24, 24] [6, 1, 5, 5] [6] max_pool2d_4 [3, 6, 12, 12] conv2d_7 [3, 16, 8, 8] [16, 6, 5, 5] [16] max_pool2d_5 [3, 16, 4, 4] conv2d_8 [3, 120, 1, 1] [120, 16, 4, 4] [120] linear_4 [3, 64] [120, 64] [64] linear_5 [3, 10] [64, 10] [10]
与我们的计算一致
这里卷积核的参数也要着重理解一下,第一层就是六个5×5的卷积核,很简单。
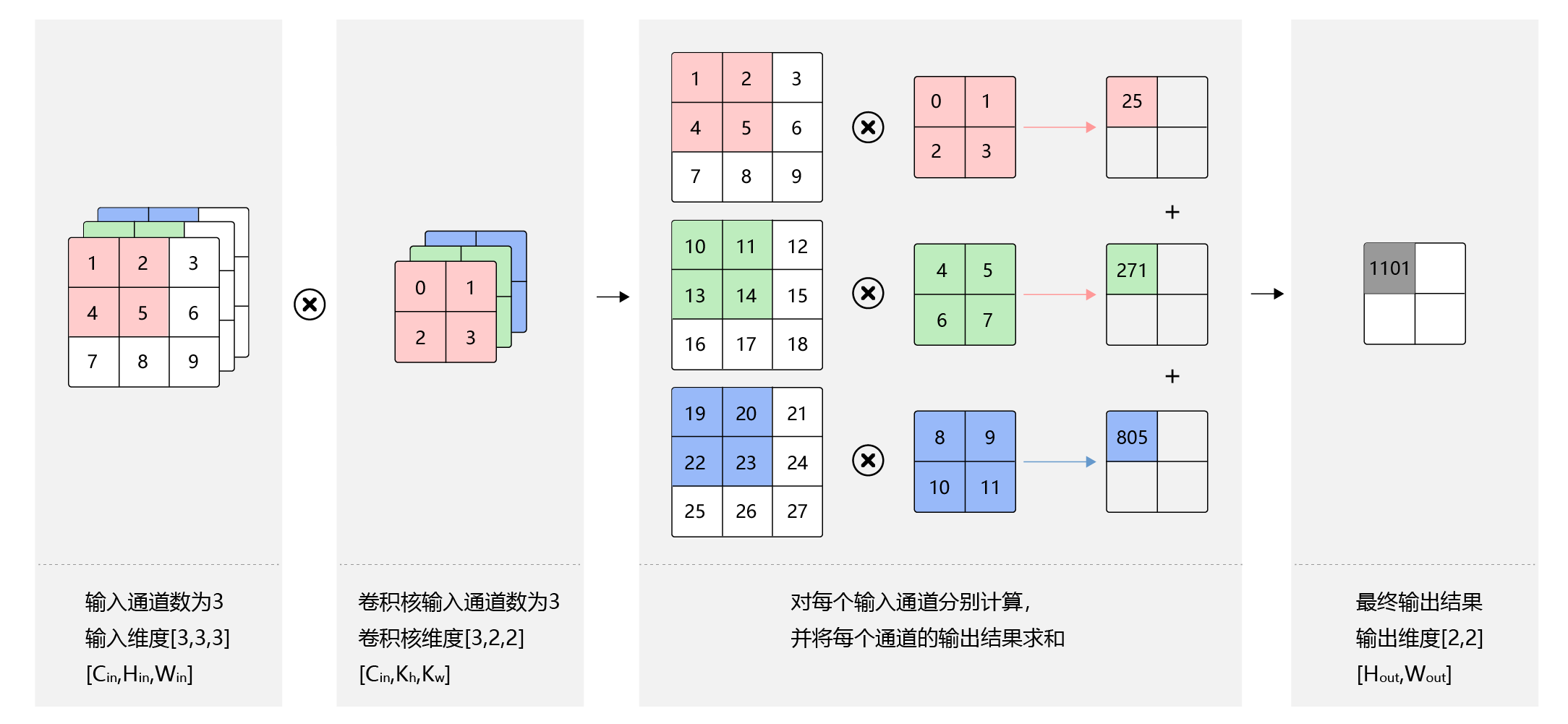
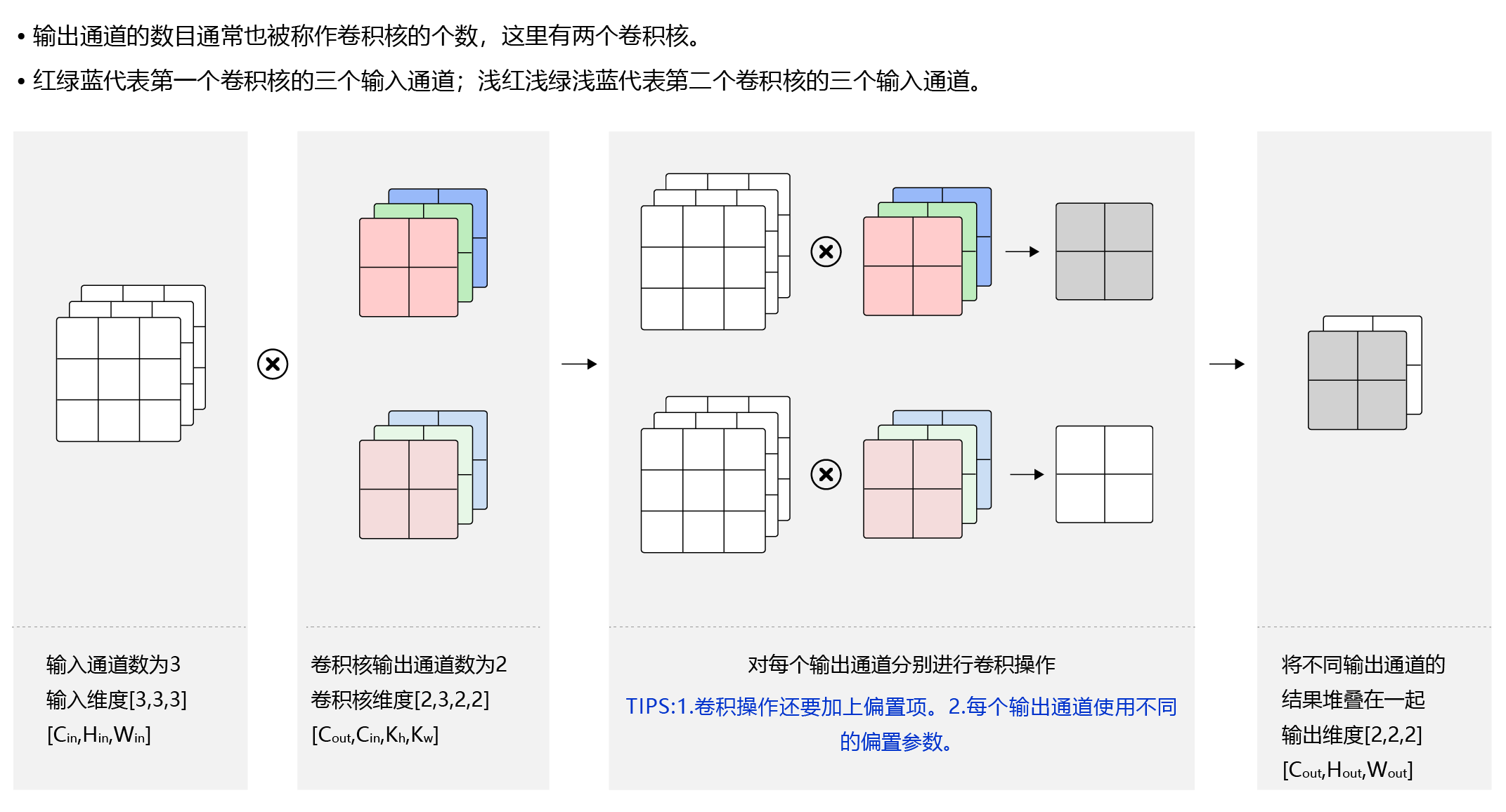
第二层卷积是6通道->16通道,输出的每一个通道都是上一步结果6个通道卷积出来在相加的结果,也就是一共6×16个卷积核,可以结合下图理解
多通道输入
多通道输入+多通道输出
下面进行训练,和之前的手写数字识别的代码没有区别,只是model的结构改成了LeNet
# -*- coding: utf-8 -*-
# LeNet 识别手写数字
import os
import random
import paddle
import numpy as np
# 定义训练过程
def train(model):
# 开启0号GPU训练
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
print('start training ... ')
model.train()
epoch_num = 5
opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters())
# 使用Paddle自带的数据读取器
train_loader = paddle.batch(paddle.dataset.mnist.train(), batch_size=10)
valid_loader = paddle.batch(paddle.dataset.mnist.test(), batch_size=10)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
# 调整输入数据形状和类型
x_data = np.array([item[0] for item in data], dtype='float32').reshape(-1, 1, 28, 28)
y_data = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)
# 将numpy.ndarray转化成Tensor
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 计算模型输出
logits = model(img)
# 计算损失函数
loss = F.softmax_with_cross_entropy(logits, label)
avg_loss = paddle.mean(loss)
if batch_id % 1000 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
avg_loss.backward()
opt.step()
opt.clear_grad()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
# 调整输入数据形状和类型
x_data = np.array([item[0] for item in data], dtype='float32').reshape(-1, 1, 28, 28)
y_data = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)
# 将numpy.ndarray转化成Tensor
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 计算模型输出
logits = model(img)
pred = F.softmax(logits)
# 计算损失函数
loss = F.softmax_with_cross_entropy(logits, label)
acc = paddle.metric.accuracy(pred, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
# 保存模型参数
paddle.save(model.state_dict(), 'mnist.pdparams')
# 创建模型
model = LeNet(num_classes=10)
# 启动训练过程
train(model)接下来我们用torch来实现一遍
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
import torchvision
import json
import numpy as np
import gzip
import random
#paddle这里直接用的自带的数据读取器。我们还是用自己写的数据读取函数
def load_data(mode='train'):
datafile = r'E:NLPDATA/MNIST/mnist.json.gz'
print('loading mnist dataset from {} ......'.format(datafile))
# 加载json数据文件
data = json.load(gzip.open(datafile))
print('mnist dataset load done')
# 读取到的数据区分训练集,验证集,测试集
train_set, val_set, eval_set = data
if mode == 'train':
# 获得训练数据集
imgs, labels = train_set[0], train_set[1]
elif mode == 'valid':
# 获得验证数据集
imgs, labels = val_set[0], val_set[1]
elif mode == 'eval':
# 获得测试数据集
imgs, labels = eval_set[0], eval_set[1]
else:
raise Exception("mode can only be one of ['train', 'valid', 'eval']")
print("训练数据集数量: ", len(imgs))
# 校验数据
imgs_length = len(imgs)
assert len(imgs) == len(labels), \
"length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len(labels))
# 获得数据集长度
imgs_length = len(imgs)
# 定义数据集每个数据的序号,根据序号读取数据
index_list = list(range(imgs_length))
# 读入数据时用到的批次大小
BATCHSIZE = 100
# 定义数据生成器
def data_generator():
if mode == 'train':
# 训练模式下打乱数据
random.shuffle(index_list)
imgs_list = []
labels_list = []
for i in index_list:
# 将数据处理成希望的格式,比如类型为float32,shape为[1, 28, 28]
img = np.reshape(imgs[i], [1, 28, 28]).astype('float32')
label = np.reshape(labels[i], [1]).astype('int64')
imgs_list.append(img)
labels_list.append(label)
if len(imgs_list) == BATCHSIZE:
# 获得一个batchsize的数据,并返回
yield np.array(imgs_list), np.array(labels_list)
# 清空数据读取列表
imgs_list = []
labels_list = []
# 如果剩余数据的数目小于BATCHSIZE,
# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batch
if len(imgs_list) > 0:
yield np.array(imgs_list), np.array(labels_list)
return data_generator
#定义模型结构
from torch.nn import Conv2d, MaxPool2d, Linear
class Mnist(nn.Module):
def __init__(self):
super(Mnist, self).__init__()
self.conv1 = Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.max_pool1 = MaxPool2d(kernel_size=2, stride=2)
self.conv2 = Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.max_pool2 = MaxPool2d(kernel_size=2, stride=2)
self.conv3 = Conv2d(in_channels=16, out_channels=120, kernel_size=4)
self.fc1 = Linear(in_features=120, out_features=64)
self.fc2 = Linear(in_features=64, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = torch.sigmoid(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = torch.sigmoid(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = torch.sigmoid(x)
x = torch.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
return x
# 训练配置,并启动训练过程
model = Mnist()
model = model.cuda()
model.train(mode=True)
#调用加载数据的函数
train_loader = load_data('train')
optimizer = optim.Adam(model.parameters(), lr=0.001)
BATCHSIZE = 100
EPOCH_NUM = 10
for epoch_id in range(EPOCH_NUM):
correct = 0
for batch_id, data in enumerate(train_loader()):
#准备数据,变得更加简洁
image_data, label_data = data
image = torch.tensor(image_data).cuda()
label = torch.tensor(label_data).cuda()
#image = torch.reshape(image, [image.shape[0], 1, 28, 28])
#前向计算的过程
if batch_id == 0 and epoch_id == 0:
predict = model(image)
elif batch_id == 401:
predict = model(image)
else:
predict = model(image)
predict_label = torch.max(predict, 1)[1]
correct += (predict_label == label.squeeze(dim=1)).sum()
#计算损失,取一个批次样本损失的平均值
loss = F.cross_entropy(predict, label.squeeze(dim=1)).cuda()
avg_loss = torch.mean(loss)
#每训练了150批次的数据,打印下当前Loss的情况
if batch_id != 0 and batch_id % 150 == 0:
print("epoch: {}, batch: {}, loss is: {}, Accuracy:{:.3f}".format(epoch_id, batch_id, avg_loss.cpu().detach().numpy(),\
correct/(BATCHSIZE*150)))
correct = 0
#后向传播,更新参数的过程
avg_loss.backward()
optimizer.step()
model.zero_grad()
torch.save(model.state_dict(), 'mnist_test.pdparams')//torch的保存state_dict一定一定要加括号,torch要不要加括号真的迷这里没有输出每个epoch开始,batch_id=0时的accuracy,主要是图省事,每个epoch最后一组不足150batch的不太方便算,应该用个list把每个batch的accuracy装起来求个mean,懒得改了。

Comments NOTHING