

GitHub - CnTransGroup/EffectiveModernCppChinese: 《Effective Modern C++》- 完成翻译
第一章 类型推导
条款1 理解模板类型推导
template<typename T>
void f(ParamType param){...};
f(expr);在编译期,编译器会通过expr推导俩个型别(T,ParamType),ParamType常会包含一些饰词,如const或引用。例如:
template<typename T>
void f(const T& param){...};
int x = 0;
f(x);T被推导为int,而ParamType被推导为const int&
大部分情况下模板函数的类别推导是很想当然的,但也有一些特殊情况,需要分三种情况讨论。
- ParamType具有指针或引用类别,但不是个万能引用
- ParamType是一个万能引用
- ParamType既非指针也非引用
情况1:ParamType具有指针或引用类别,但不是个万能引用
最简单的情况,规则如下:
1若expr具有引用型别,先将引用部分忽略
2尔后,对expr的型别和ParamType的型别执行模式匹配来决定T的类别
template<typename T>
void f(T& param);
//void f(T&& param) 右值引用规律一致
int x = 27;
const int cx = x;
const int& rx = x;
f(x); //T的型别是int,param的型别是int&
f(cx); //T的型别是const int,param的型别是const int&
f(rx); //T的型别是const int,param的型别是const int&
//向T&类别的模板传入const对象是安全的,该对象的常量性会成为T的型别推导结果的组成部分
//即使rx具有引用类别,T也未被推导成一个引用,因为rx的引用性会在型别推导过程中被忽略
//形参改为const T&,由于现在已经假定param具有const引用型别,因此对于T的型别推导中包含const就没有必要了
template<typename T>
void f(const T& param);
int x = 27;
const int cx = x;
const int& rx = x;
f(x); //T的型别是int,param的型别是const int&
f(cx); //T的型别是int,param的型别是const int&
f(rx); //T的型别是int,param的型别是const int&
//如果param是个指针
template<typename T>
void f(T* param);
int x = 27;
const int *px = &x;
f(&x); //T的型别是int,param的型别是int*
f(px); //T的型别是const int,param的型别是const int*情况2:ParamType是个万能引用
对于万能引用形参的模板而言,规则稍复杂一点
1如果expr是个左值,T和ParamType都会被推导为左值引用。这个结果具有双重的奇特之处:首先,这是在模板型别推到中,T被推导为引用型别的唯一情形。其次,尽管在声明时使用的是右值引用语法,它的型别推导结果却是左值引用。
2如果expr是个右值,则应用情况1的规则
template<typename T>
voif f(T&& param);
int x = 27;
const int cx = x;
const int& rx = x;
f(x); //x是左值,所以T的型别是int&,param的型别也是int&
f(cx); //cx是左值,所以T的型别是const int&,param的型别也是const int&
f(rx); //rx是左值,所以T的型别是const int&,param的型别也是const int&
f(27); //27是个右值,所以T的型别是int,这么一来,param的型别就成了int&&情况3:ParamType既非指针也非引用
当ParamType既非指针也非引用时,我们面对的就是所谓按值传递
1一如之前,若expr具有引用型别,则忽略其引用部分
2忽略expr的引用性之后,若expr是个const对象,也忽略
template<typename T>
voif f(T param); //按值传递,无论传入什么都只会是一个副本
int x = 27;
const int cx = x;
const int& rx = x;
f(x); //T和param的型别都是int
f(cx); //T和param的型别都是int
f(rx); //T和param的型别都是int需要重点说明的是,const仅会在按值形参处被忽略。考虑expr是个指向const对象的const指针,且expr按值传给param。
template<typename T>
voif f(T param); //按值传递,无论传入什么都只会是一个副本
const char* const ptr = "fun with pointers";
f(ptr); //param为const char *数组实参
数组型别有别于指针型别,尽管有时他们看起来可以互换。形成这种假象的主要原因是,在很多语境下,数组会退化成指向其首元素的指针。
const char name[] = "J.P.Briggs"; //name的型别是const char[13]
const char * ptrToName = name; //数组退化成指针当一个数组传递给持有按值形参的模板时
template<typename T>
voif f(T param);
f(name);//name是个数组,但T的型别被推导为const char*如果将模板函数修改成引用
template<typename T>
voif f(T& param);
f(name); //T被推导为数组并包含数组尺寸(const char[13]) 而f的形参对被推导为const char(&)[13]
利用这一能力我们可以创造出一个模板来推导出数组含有的元素个数
//将函数声明为consexpr,能够使得返回值在编译期就可用。从而就可以在声明一组数组时,指定其尺寸和另一数组相同
template<typename T,std::size_t N>
constexpr std::size_t arraySize(T (&)[N]) noexcept{return N;}
int keyVals[] = {1,3,5,7,9};
int mappedVals[arraySize[keyVals]];
//使用std::array
std::array<int,arraySize(keyVals)> mappedVals;函数实参
数组并非唯一可以退化为指针之物,函数也会退化成函数指针
void someFunc(int,double);
template<typename T>
void f1(T param);
template f2(T& param);
void f2(T& param)
f1(someFunc); //param被推导为函数指针 void(*)(int,double)
f2(someFunc); //param被推导为函数引用 void(&)(int,double)条款2 理解auto型别推导
除了一个奇妙的例外情况意外,auto型别推导就是模板型别推导
//模板函数中编译器会利用expr来推导T和ParamType的型别
template<typename T>
void f(ParamType param);
//当变量采用auto来声明的时候,auto就扮演了T的角色,而变量的型别修饰词则扮演的是ParamType的角色
auto x = 27; //x的型别修饰词就是auto自身
const auto cx = x; //x的型别修饰词是const auto
const auto& rx = x; //x的型别修饰词是const auto&与模板函数一样也分三种情况讨论
- 情况1:型别饰词是指针或引用,但不是万能引用
- 情况2:型别饰词是万能引用
- 情况3:型别饰词既非指针也非引用
情况1和3如上段代码所示,情况2也很正常
auto&& uref1 = x; //x的型别是int,且是左值,所以uref1的型别是int&
auto&& uref2 = cx; //cx的型别是const int,且是左值,所以uref2的型别是const int&
auto&& uref3 = 27; //27的型别是int,且是右值,所以uref3的型别是int&&数组和函数在非引用型别饰词的前提下退化成指针同样适用于auto型别推导
const char name[] = "J.P.Briggs"; //name的型别是const char[13]
auto arr1 = name; //arr1的型别是const char*
auto& arr2 = name; //arr2的型别是const char (&)[13]
void someFunc(int,double); //someFunc是个函数,型别是void(int,double)
auto func1 = someFunc; //func1的型别是void(*)(int,double)
auto& func2 = someFunc; //func2的型别是void(&)(int,double)特殊的一种情况
关于使用{}的auto自动推导情况,涉及std::initializer_list
条款3:理解decltype
decltype是一个奇怪的东西。给它一个名字或者表达式decltype就会告诉你这个名字或者表达式的类型。
在C++11中,decltype最主要的用途就是用于声明函数模板,而这个函数返回类型依赖于形参类型。
template<typename Container, typename Index> //可以工作,
auto authAndAccess(Container& c, Index i) //但是需要改良
->decltype(c[i])
{
authenticateUser();
return c[i];
}函数名称前面的auto不会做任何的类型推导工作。相反的,他只是暗示使用了C++11的尾置返回类型语法,即在函数形参列表后面使用一个”->“符号指出函数的返回类型,尾置返回类型的好处是我们可以在函数返回类型中使用函数形参相关的信息。在authAndAccess函数中,我们使用c和i指定返回类型。如果我们按照传统语法把函数返回类型放在函数名称之前,c和i就未被声明所以不能使用。
C++11允许自动推导单一语句的lambda表达式的返回类型, C++14扩展到允许自动推导所有的lambda表达式和函数,甚至它们内含多条语句。对于authAndAccess来说这意味着在C++14标准下我们可以忽略尾置返回类型,只留下一个auto。使用这种声明形式,auto标示这里会发生类型推导。更准确的说,编译器将会从函数实现中推导出函数的返回类型。
template<typename Container, typename Index> //C++14版本,
auto authAndAccess(Container& c, Index i) //不那么正确
{
authenticateUser();
return c[i]; //从c[i]中推导返回类型
}Item2解释了函数返回类型中使用auto,编译器实际上是使用的模板类型推导的那套规则。如果那样的话这里就会有一些问题。正如我们之前讨论的,operator[]对于大多数T类型的容器会返回一个T&,但是Item1解释了在模板类型推导期间,表达式的引用性(reference-ness)会被忽略。基于这样的规则,考虑它会对下面用户的代码有哪些影响:
std::deque<int> d;
…
authAndAccess(d, 5) = 10; //认证用户,返回d[5],
//然后把10赋值给它
//无法通过编译器!条款4:学会查看类型推导结果
查看编译器的推到结果以及运行时输出,但是IDE的推导并不一定百分百正确
第二章 auto
条款5: 优先考虑auto而非显式类型声明
条款6:auto推导若非己愿,使用显式类型初始化惯用法
注意vector<bool>等造成的特殊情况,使用显示声明
std::vector<bool> features(const Widget& w);
auto highPriority = static_cast<bool>(features(w)[5]);或者明确表示我要减少数据精度
double calcEpsilon();
//float ep = calcEpsilon(); //非显式
auto ep = static_cast<float>(calcEpsilon());第三章 转向现代C++
条款7:区别使用()和{}创建对象
C++11使用统一初始化(uniform initialization)来整合这些混乱且不适于所有情景的初始化语法,所谓统一初始化是指在任何涉及初始化的地方都使用单一的初始化语法。 它基于花括号,出于这个原因我更喜欢称之为括号初始化。
std::vector<int> v{ 1, 3, 5 }; //v初始内容为1,3,5括号表达式还有一个少见的特性,即它不允许内置类型间隐式的变窄转换(narrowing conversion)。如果一个使用了括号初始化的表达式的值,不能保证由被初始化的对象的类型来表示,代码就不会通过编译:
double x, y, z;
int sum1{ x + y + z }; //错误!double的和可能不能表示为int另一个值得注意的特性是括号表达式对于C++最令人头疼的解析问题有天生的免疫性。(译注:所谓最令人头疼的解析即most vexing parse,更多信息请参见https://en.wikipedia.org/wiki/Most_vexing_parse。)C++规定任何可以被解析为一个声明的东西必须被解析为声明。这个规则的副作用是让很多程序员备受折磨:他们可能想创建一个使用默认构造函数构造的对象,却不小心变成了函数声明。问题的根源是如果你调用带参构造函数,你可以这样做:
Widget w1(10); //使用实参10调用Widget的一个构造函数
Widget w2(); //最令人头疼的解析!声明一个函数w2,返回Widget
Widget w3{}; //调用没有参数的构造函数构造对象括号初始化的缺点是有时它有一些令人惊讶的行为。这些行为使得括号初始化、std::initializer_list和构造函数参与重载决议时本来就不清不楚的暧昧关系进一步混乱。把它们放到一起会让看起来应该左转的代码右转。举个例子,Item2解释了当auto声明的变量使用花括号初始化,变量类型会被推导为std::initializer_list,但是使用相同内容的其他初始化方式会产生更符合直觉的结果。所以,你越喜欢用auto,你就越不能用括号初始化。
尤其注意std::initializer_list带来的影响,当你给一个类添加一个包含std::initializer_list形参的构造函数时,可能会导致已有代码错误调用至新构造函数。
这里还有一个有趣的边缘情况。假如你使用的花括号初始化是空集,并且你欲构建的对象有默认构造函数,也有std::initializer_list构造函数。你的空的花括号意味着什么?如果它们意味着没有实参,就该使用默认构造函数,但如果它意味着一个空的std::initializer_list,就该调用std::initializer_list构造函数。
最终会调用默认构造函数。空的花括号意味着没有实参,不是一个空的std::initializer_list:
class Widget {
public:
Widget(); //默认构造函数
Widget(std::initializer_list<int> il); //std::initializer_list构造函数
… //没有隐式转换函数
};
Widget w1; //调用默认构造函数
Widget w2{}; //也调用默认构造函数
Widget w3(); //最令人头疼的解析!声明一个函数如果你想用空std::initializer来调用std::initializer_list构造函数,你就得创建一个空花括号作为函数实参——把空花括号放在圆括号或者另一个花括号内来界定你想传递的东西。
Widget w4({}); //使用空花括号列表调用std::initializer_list构造函数
Widget w5{{}}; //同上此时,括号初始化,std::initializer_list和构造函数重载的晦涩规则就会一下子涌进你的脑袋,你可能会想研究半天这些东西在你的日常编程中到底占多大比例。可能比你想象的要有用。因为std::vector作为受众之一会直接受到影响。std::vector有一个非std::initializer_list构造函数允许你去指定容器的初始大小,以及使用一个值填满你的容器。但它也有一个std::initializer_list构造函数允许你使用花括号里面的值初始化容器。如果你创建一个数值类型的std::vector(比如std::vector<int>),然后你传递两个实参,把这两个实参放到圆括号和放到花括号中有天壤之别:
std::vector<int> v1(10, 20); //使用非std::initializer_list构造函数
//创建一个包含10个元素的std::vector,
//所有的元素的值都是20
std::vector<int> v2{10, 20}; //使用std::initializer_list构造函数
//创建包含两个元素的std::vector,
//元素的值为10和20条款8:优先考虑nullptr而非0和NULL
模板类型推导将0和NULL推导为一个错误的类型(即它们的实际类型,而不是作为空指针的隐含意义),这就导致在当你想要一个空指针时,它们的替代品nullptr很吸引人。使用nullptr,模板不会有什么特殊的转换。另外,使用nullptr不会让你受到同重载决议特殊对待0和NULL一样的待遇。当你想用一个空指针,使用nullptr,不用0或者NULL。
条款9:优先考虑别名声明而非typedef
//FP是一个指向函数的指针的同义词,它指向的函数带有
//int和const std::string&形参,不返回任何东西
typedef void (*FP)(int, const std::string&); //typedef
//含义同上
using FP = void (*)(int, const std::string&); //别名声明当然,两个结构都不是非常让人满意,没有人喜欢花大量的时间处理函数指针类型的别名(译注:指FP),所以至少在这里,没有一个吸引人的理由让你觉得别名声明比typedef好。
不过有一个地方使用别名声明吸引人的理由是存在的:模板。特别地,别名声明可以被模板化(这种情况下称为别名模板alias templates)但是typedef不能。这使得C++11程序员可以很直接的表达一些C++98中只能把typedef嵌套进模板化的struct才能表达的东西。考虑一个链表的别名,链表使用自定义的内存分配器,MyAlloc。使用别名模板,这真是太容易了:
template<typename T> //MyAllocList<T>是
using MyAllocList = std::list<T, MyAlloc<T>>; //std::list<T, MyAlloc<T>>
//的同义词
MyAllocList<Widget> lw; //用户代码C++11在type traits(类型特性)中给了你一系列工具去实现类型转换,如果要使用这些模板请包含头文件<type_traits>。里面有许许多多type traits,也不全是类型转换的工具,也包含一些可预测接口的工具。给一个你想施加转换的类型T,结果类型就是std::transformation<T>::type。
尽管写了一些,但我这里不是想给你一个关于type traits使用的教程。注意类型转换尾部的::type。如果你在一个模板内部将他们施加到类型形参上(实际代码中你也总是这么用),你也需要在它们前面加上typename。至于为什么要这么做是因为这些C++11的type traits是通过在struct内嵌套typedef来实现的。是的,它们使用类型同义词(译注:根据上下文指的是使用typedef的做法)技术实现,而正如我之前所说这比别名声明要差。
关于为什么这么实现是有历史原因的,但是我们跳过它(我认为太无聊了),因为标准委员会没有及时认识到别名声明是更好的选择,所以直到C++14它们才提供了使用别名声明的版本。这些别名声明有一个通用形式:对于C++11的类型转换std::transformation<T>::type在C++14中变成了std::transformation_t。举个例子或许更容易理解:
std::remove_const<T>::type //从const T中产出T
std::remove_reference<T>::type //从T&和T&&中产出T
std::add_lvalue_reference<T>::type //从T中产出T&
std::remove_const<T>::type //C++11: const T → T
std::remove_const_t<T> //C++14 等价形式
std::remove_reference<T>::type //C++11: T&/T&& → T
std::remove_reference_t<T> //C++14 等价形式
std::add_lvalue_reference<T>::type //C++11: T → T&
std::add_lvalue_reference_t<T> //C++14 等价形式
template <class T>
using remove_const_t = typename remove_const<T>::type;
template <class T>
using remove_reference_t = typename remove_reference<T>::type;
template <class T>
using add_lvalue_reference_t =
typename add_lvalue_reference<T>::type; 条款10:优先考虑限域enum而非未限域enum
通常来说,在花括号中声明一个名字会限制它的作用域在花括号之内。但这对于C++98风格的enum中声明的枚举名(译注:enumerator,连同下文“枚举名”都指enumerator)是不成立的。这些枚举名的名字(译注:enumerator names,连同下文“名字”都指names)属于包含这个enum的作用域,这意味着作用域内不能含有相同名字的其他东西:
enum Color { black, white, red }; //black, white, red在
//Color所在的作用域
auto white = false; //错误! white早已在这个作用
//域中声明这些枚举名的名字泄漏进它们所被定义的enum在的那个作用域,这个事实有一个官方的术语:未限域枚举(unscoped enum)。在C++11中它们有一个相似物,限域枚举(scoped enum),它不会导致枚举名泄漏:
enum class Color { black, white, red }; //black, white, red
//限制在Color域内
auto white = false; //没问题,域内没有其他“white”
Color c = white; //错误,域中没有枚举名叫white
Color c = Color::white; //没问题
auto c = Color::white; //也没问题(也符合Item5的建议)因为限域enum是通过“enum class”声明,所以它们有时候也被称为枚举类(enum classes)。
使用限域enum来减少命名空间污染,这是一个足够合理使用它而不是它的同胞未限域enum的理由,其实限域enum还有第二个吸引人的优点:在它的作用域中,枚举名是强类型。未限域enum中的枚举名会隐式转换为整型(现在,也可以转换为浮点类型)。因此下面这种歪曲语义的做法也是完全有效的:
enum Color { black, white, red }; //未限域enum
std::vector<std::size_t> //func返回x的质因子
primeFactors(std::size_t x);
Color c = red;
…
if (c < 14.5) { // Color与double比较 (!)
auto factors = // 计算一个Color的质因子(!)
primeFactors(c);
…
}
enum class Color { black, white, red }; //Color现在是限域enum
Color c = Color::red; //和之前一样,只是
... //多了一个域修饰符
if (c < 14.5) { //错误!不能比较
//Color和double
auto factors = //错误!不能向参数为std::size_t
primeFactors(c); //的函数传递Color参数
…
}如果你真的很想执行Color到其他类型的转换,和平常一样,使用正确的类型转换运算符扭曲类型系统:
if (static_cast<double>(c) < 14.5) { //奇怪的代码,
//但是有效
auto factors = //有问题,但是
primeFactors(static_cast<std::size_t>(c)); //能通过编译
…
}此外枚举类型可以前置声明以及设置底层型别
要为非限域enum指定底层类型,你可以同上,结果就可以前向声明:
enum Color: std::uint8_t; //非限域enum前向声明
//底层类型为
//std::uint8_t底层类型说明也可以放到enum定义处:
enum class Status: std::uint32_t { good = 0,
failed = 1,
incomplete = 100,
corrupt = 200,
audited = 500,
indeterminate = 0xFFFFFFFF
};非限域enum与tuple协作使用
using UserInfo = //类型别名,参见Item9
std::tuple<std::string, //名字
std::string, //email地址
std::size_t> ; //声望
enum UserInfoFields { uiName, uiEmail, uiReputation };
UserInfo uInfo; //同之前一样
…
auto val = std::get<uiEmail>(uInfo); //啊,获取用户email字段的值之所以它能正常工作是因为UserInfoFields中的枚举名隐式转换成std::size_t了,其中std::size_t是std::get模板实参所需的。
对应的限域enum版本就很啰嗦了:
enum class UserInfoFields { uiName, uiEmail, uiReputation };
UserInfo uInfo; //同之前一样
…
auto val =
std::get<static_cast<std::size_t>(UserInfoFields::uiEmail)>
(uInfo);为避免这种冗长的表示,我们可以写一个函数传入枚举名并返回对应的std::size_t值,但这有一点技巧性。std::get是一个模板(函数),需要你给出一个std::size_t值的模板实参(注意使用<>而不是()),因此将枚举名变换为std::size_t值的函数必须在编译期产生这个结果。如Item15提到的,那必须是一个constexpr函数。
事实上,它也的确该是一个constexpr函数模板,因为它应该能用于任何enum。如果我们想让它更一般化,我们还要泛化它的返回类型。较之于返回std::size_t,我们更应该返回枚举的底层类型。这可以通过std::underlying_type这个type trait获得。(参见Item9关于type trait的内容)。最终我们还要再加上noexcept修饰(参见Item14),因为我们知道它肯定不会产生异常。根据上述分析最终得到的toUType函数模板在编译期接受任意枚举名并返回它的值:
template<typename E>
constexpr typename std::underlying_type<E>::type
toUType(E enumerator) noexcept
{
return
static_cast<typename
std::underlying_type<E>::type>(enumerator);
}在C++14中,toUType还可以进一步用std::underlying_type_t(参见Item9)代替typename std::underlying_type<E>::type打磨:
template<typename E> //C++14
constexpr std::underlying_type_t<E>
toUType(E enumerator) noexcept
{
return static_cast<std::underlying_type_t<E>>(enumerator);
}还可以再用C++14 auto(参见Item3)打磨一下代码:
template<typename E> //C++14
constexpr auto
toUType(E enumerator) noexcept
{
return static_cast<std::underlying_type_t<E>>(enumerator);
}不管它怎么写,toUType现在允许这样访问tuple的字段了:
auto val = std::get<toUType(UserInfoFields::uiEmail)>(uInfo);条款11:优先考虑使用deleted函数而非使用未定义的私有声明
在C++98中防止调用这些函数的方法是将它们声明为私有(private)成员函数并且不定义。
将它们声明为私有成员可以防止客户端调用这些函数。故意不定义它们意味着假如还是有代码用它们(比如成员函数或者类的友元friend),就会在链接时引发缺少函数定义(missing function definitions)错误。
在C++11中有一种更好的方式达到相同目的:用“= delete”将拷贝构造函数和拷贝赋值运算符标记为deleted函数(译注:一些文献翻译为“删除的函数”)。
template <class charT, class traits = char_traits<charT> >
class basic_ios : public ios_base {
public:
…
private:
basic_ios(const basic_ios& ); // not defined
basic_ios& operator=(const basic_ios&); // not defined
};
template <class charT, class traits = char_traits<charT> >
class basic_ios : public ios_base {
public:
…
basic_ios(const basic_ios& ) = delete;
basic_ios& operator=(const basic_ios&) = delete;
…
};如果要将老代码的“私有且未定义”函数替换为deleted函数时请一并修改它的访问性为public,这样可以让编译器产生更好的错误信息。
deleted函数还有一个重要的优势是任何函数都可以标记为deleted,而只有成员函数可被标记为private。(译注:从下文可知“任何”是包含普通函数和成员函数等所有可声明函数的地方,而private方法只适用于成员函数)假如我们有一个非成员函数,它接受一个整型参数,检查它是否为幸运数:
bool isLucky(int number);C++有沉重的C包袱,使得含糊的、能被视作数值的任何类型都能隐式转换为int,但是有一些调用可能是没有意义的:
if (isLucky('a')) … //字符'a'是幸运数?
if (isLucky(true)) … //"true"是?
if (isLucky(3.5)) … //难道判断它的幸运之前还要先截尾成3?如果幸运数必须真的是整型,我们该禁止这些调用通过编译。
其中一种方法就是创建deleted重载函数,其参数就是我们想要过滤的类型:
bool isLucky(int number); //原始版本
bool isLucky(char) = delete; //拒绝char
bool isLucky(bool) = delete; //拒绝bool
bool isLucky(double) = delete; //拒绝float和double另一个deleted函数用武之地(private成员函数做不到的地方)是禁止一些模板的实例化。假如你要求一个模板仅支持原生指针(尽管第四章建议使用智能指针代替原生指针):
template<typename T>
void processPointer(T* ptr);在指针的世界里有两种特殊情况。一是void*指针,因为没办法对它们进行解引用,或者加加减减等。另一种指针是char*,因为它们通常代表C风格的字符串,而不是正常意义下指向单个字符的指针。这两种情况要特殊处理,在processPointer模板里面,我们假设正确的函数应该拒绝这些类型。也即是说,processPointer不能被void*和char*调用。
template<>
void processPointer<void>(void*) = delete;
template<>
void processPointer<char>(char*) = delete;现在如果使用void*和char*调用processPointer就是无效的,按常理说const void*和const char*也应该无效,所以这些实例也应该标注delete:
template<>
void processPointer<const void>(const void*) = delete;
template<>
void processPointer<const char>(const char*) = delete;如果你想做得更彻底一些,你还要删除const volatile void*和const volatile char*重载版本,另外还需要一并删除其他标准字符类型的重载版本:std::wchar_t,std::char16_t和std::char32_t。
有趣的是,如果类里面有一个函数模板,你可能想用private(经典的C++98惯例)来禁止这些函数模板实例化,但是不能这样做,因为不能给特化的成员模板函数指定一个不同于主函数模板的访问级别。如果processPointer是类Widget里面的模板函数, 你想禁止它接受void*参数,那么通过下面这样C++98的方法就不能通过编译:
class Widget {
public:
…
template<typename T>
void processPointer(T* ptr)
{ … }
private:
template<> //错误!
void processPointer<void>(void*);
};问题是模板特例化必须位于一个命名空间作用域,而不是类作用域。deleted函数不会出现这个问题,因为它不需要一个不同的访问级别,且他们可以在类外被删除(因此位于命名空间作用域):
class Widget {
public:
…
template<typename T>
void processPointer(T* ptr)
{ … }
…
};
template<> //还是public,
void Widget::processPointer<void>(void*) = delete; //但是已经被删除了条款13:使用override声明重写函数
在C++面向对象的世界里,涉及的概念有类,继承,虚函数。这个世界最基本的概念是派生类的虚函数重写基类同名函数。令人遗憾的是虚函数重写可能一不小心就错了。似乎这部分语言的设计理念是不仅仅要遵守墨菲定律,还应该尊重它。
虽然“重写(overriding)”听起来像“重载(overloading)”,然而两者完全不相关,所以让我澄清一下,正是虚函数重写机制的存在,才使我们可以通过基类的接口调用派生类的成员函数:
class Base {
public:
virtual void doWork(); //基类虚函数
…
};
class Derived: public Base {
public:
virtual void doWork(); //重写Base::doWork
… //(这里“virtual”是可以省略的)
};
std::unique_ptr<Base> upb = //创建基类指针指向派生类对象
std::make_unique<Derived>(); //关于std::make_unique
… //请参见Item21
upb->doWork(); //通过基类指针调用doWork,
//实际上是派生类的doWork
//函数被调用要想重写一个函数,必须满足下列要求:
- 基类函数必须是
virtual - 基类和派生类函数名必须完全一样(除非是析构函数)
- 基类和派生类函数形参类型必须完全一样
- 基类和派生类函数常量性
constness必须完全一样 - 基类和派生类函数的返回值和异常说明(exception specifications)必须兼容
除了这些C++98就存在的约束外,C++11又添加了一个:
- 函数的引用限定符(reference qualifiers)必须完全一样。成员函数的引用限定符是C++11很少抛头露脸的特性,所以如果你从没听过它无需惊讶。它可以限定成员函数只能用于左值或者右值。成员函数不需要
virtual也能使用它们:
class Widget {
public:
…
void doWork() &; //只有*this为左值的时候才能被调用
void doWork() &&; //只有*this为右值的时候才能被调用
};
…
Widget makeWidget(); //工厂函数(返回右值)
Widget w; //普通对象(左值)
…
w.doWork(); //调用被左值引用限定修饰的Widget::doWork版本
//(即Widget::doWork &)
makeWidget().doWork(); //调用被右值引用限定修饰的Widget::doWork版本
//(即Widget::doWork &&)比起让编译器(译注:通过warnings)告诉你想重写的而实际没有重写,不如给你的派生类重写函数全都加上override。
条款13:优先考虑const_iterator而非iterator
STL const_iterator等价于指向常量的指针(pointer-to-const)。它们都指向不能被修改的值。标准实践是能加上const就加上,这也指示我们需要一个迭代器时只要没必要修改迭代器指向的值,就应当使用const_iterator。
上面的说法对C++11和C++98都是正确的,但是在C++98中,标准库对const_iterator的支持不是很完整。首先不容易创建它们,其次就算你有了它,它的使用也是受限的。假如你想在std::vector<int>中查找第一次出现1983(C++代替C with classes的那一年)的位置,然后插入1998(第一个ISO C++标准被接纳的那一年)。如果vector中没有1983,那么就在vector尾部插入。在C++98中使用iterator可以很容易做到:
std::vector<int> values;
…
std::vector<int>::iterator it =
std::find(values.begin(), values.end(), 1983);
values.insert(it, 1998);C++11中,现在const_iterator既容易获取又容易使用。容器的成员函数cbegin和cend产出const_iterator,甚至对于non-const容器也可用,那些之前使用iterator指示位置(如insert和erase)的STL成员函数也可以使用const_iterator了。使用C++11 const_iterator重写C++98使用iterator的代码也稀松平常:
std::vector<int> values; //和之前一样
…
auto it = //使用cbegin
std::find(values.cbegin(), values.cend(), 1983);//和cend
values.insert(it, 1998);条款14:如果函数不抛出异常请使用noexcept
在C++11中,无条件的noexcept保证函数不会抛出任何异常。
条款15:尽可能的使用constexpr
如果要给C++11颁一个“最令人困惑新词”奖,constexpr十有八九会折桂。当用于对象上面,它本质上就是const的加强形式,但是当它用于函数上,意思就大不相同了。有必要消除困惑,因为你绝对会用它的,特别是当你发现constexpr “正合吾意”的时候。
从概念上来说,constexpr表明一个值不仅仅是常量,还是编译期可知的。这个表述并不全面,因为当constexpr被用于函数的时候,事情就有一些细微差别了。
条款16:让const成员函数线程安全
如果我们在数学领域中工作,我们就会发现用一个类表示多项式是很方便的。在这个类中,使用一个函数来计算多项式的根是很有用的,也就是多项式的值为零的时候(译者注:通常也被叫做零点,即使得多项式值为零的那些取值)。这样的一个函数它不会更改多项式。所以,它自然被声明为const函数。
计算多项式的根是很复杂的,因此如果不需要的话,我们就不做。如果必须做,我们肯定不想再做第二次。所以,如果必须计算它们,就缓存多项式的根,然后实现roots来返回缓存的值。下面是最基本的实现:
class Polynomial {
public:
using RootsType = std::vector<double>;
RootsType roots() const
{
if (!rootsAreValid) { //如果缓存不可用
… //计算根
//用rootVals存储它们
rootsAreValid = true;
}
return rootVals;
}
private:
mutable bool rootsAreValid{ false }; //初始化器(initializer)的
mutable RootsType rootVals{}; //更多信息请查看条款7
};从概念上讲,roots并不改变它所操作的Polynomial对象。但是作为缓存的一部分,它也许会改变rootVals和rootsAreValid的值。这就是mutable的经典使用样例,这也是为什么它是数据成员声明的一部分。
假设现在有两个线程同时调用Polynomial对象的roots方法。roots是const成员函数,那就表示着它是一个读操作。在没有同步的情况下,让多个线程执行读操作是安全的。它最起码应该做到这点。在本例中却没有做到线程安全。因为在roots中,这些线程中的一个或两个可能尝试修改成员变量rootsAreValid和rootVals。这就意味着在没有同步的情况下,这些代码会有不同的线程读写相同的内存,这就是数据竞争(data race)的定义。这段代码的行为是未定义的。
问题就是roots被声明为const,但不是线程安全的。const声明在C++11中与在C++98中一样正确(检索多项式的根并不会更改多项式的值),因此需要纠正的是线程安全的缺乏。
解决这个问题最普遍简单的方法就是——使用mutex(互斥量):
class Polynomial {
public:
using RootsType = std::vector<double>;
RootsType roots() const
{
std::lock_guard<std::mutex> g(m); //锁定互斥量
if (!rootsAreValid) { //如果缓存无效
… //计算/存储根值
rootsAreValid = true;
}
return rootsVals;
} //解锁互斥量
private:
mutable std::mutex m;
mutable bool rootsAreValid { false };
mutable RootsType rootsVals {};
};在某些情况下,互斥量的副作用显会得过大。例如,如果你所做的只是计算成员函数被调用了多少次,使用std::atomic 修饰的计数器(保证其他线程视它的操作为不可分割的整体,参见item40)通常会是一个开销更小的方法。(然而它是否轻量取决于你使用的硬件和标准库中互斥量的实现。)以下是如何使用std::atomic来统计调用次数。
class Point { //2D点
public:
…
double distanceFromOrigin() const noexcept //noexcept的使用
{ //参考条款14
++callCount; //atomic的递增
return std::sqrt((x * x) + (y * y));
}
private:
mutable std::atomic<unsigned> callCount{ 0 };
double x, y;
};条款17:理解特殊成员函数的生成
本条款中,简单记住如果支持移动就会逐成员移动类成员和基类成员,如果不支持移动就执行拷贝操作就好了。
两个拷贝操作是独立的:声明一个不会限制编译器生成另一个。两个移动操作不是相互独立的。如果你声明了其中一个,编译器就不再生成另一个。再进一步,如果一个类显式声明了拷贝操作,编译器就不会生成移动操作。
也许你早已听过_Rule of Three_规则。这个规则告诉我们如果你声明了拷贝构造函数,拷贝赋值运算符,或者析构函数三者之一,你应该也声明其余两个。它来源于长期的观察,即用户接管拷贝操作的需求几乎都是因为该类会做其他资源的管理,这也几乎意味着(1)无论哪种资源管理如果在一个拷贝操作内完成,也应该在另一个拷贝操作内完成(2)类的析构函数也需要参与资源的管理(通常是释放)。通常要管理的资源是内存,这也是为什么标准库里面那些管理内存的类(如会动态内存管理的STL容器)都声明了“the big three”:拷贝构造,拷贝赋值和析构。
Rule of Three带来的后果就是只要出现用户定义的析构函数就意味着简单的逐成员拷贝操作不适用于该类。那意味着如果一个类声明了析构,拷贝操作可能不应该自动生成,因为它们做的事情可能是错误的。在C++98提出的时候,上述推理没有得倒足够的重视,所以C++98用户声明析构函数不会左右编译器生成拷贝操作的意愿。C++11中情况仍然如此,但仅仅是因为限制拷贝操作生成的条件会破坏老代码。
Rule of Three规则背后的解释依然有效,再加上对声明拷贝操作阻止移动操作隐式生成的观察,使得C++11不会为那些有用户定义的析构函数的类生成移动操作。
所以仅当下面条件成立时才会生成移动操作(当需要时):
- 类中没有拷贝操作
- 类中没有移动操作
- 类中没有用户定义的析构
C++11对于特殊成员函数处理的规则如下:
- 默认构造函数:和C++98规则相同。仅当类不存在用户声明的构造函数时才自动生成。
- 析构函数:基本上和C++98相同;稍微不同的是现在析构默认
noexcept(参见Item14)。和C++98一样,仅当基类析构为虚函数时该类析构才为虚函数。 - 拷贝构造函数:和C++98运行时行为一样:逐成员拷贝non-static数据。仅当类没有用户定义的拷贝构造时才生成。如果类声明了移动操作它就是delete的。当用户声明了拷贝赋值或者析构,该函数自动生成已被废弃。
- 拷贝赋值运算符:和C++98运行时行为一样:逐成员拷贝赋值non-static数据。仅当类没有用户定义的拷贝赋值时才生成。如果类声明了移动操作它就是delete的。当用户声明了拷贝构造或者析构,该函数自动生成已被废弃。
- 移动构造函数和移动赋值运算符:都对非static数据执行逐成员移动。仅当类没有用户定义的拷贝操作,移动操作或析构时才自动生成。
第四章 智能指针
原始指针很难被爱的原因:
- 它的声明不能指示所指到底是单个对象还是数组。
- 它的声明没有告诉你用完后是否应该销毁它,即指针是否拥有所指之物。
- 如果你决定你应该销毁指针所指对象,没人告诉你该用
delete还是其他析构机制(比如将指针传给专门的销毁函数)。 - 如果你发现该用
delete。 原因1说了可能不知道该用单个对象形式(“delete”)还是数组形式(“delete[]”)。如果用错了结果是未定义的。 - 假设你确定了指针所指,知道销毁机制,也很难确定你在所有执行路径上都执行了恰为一次销毁操作(包括异常产生后的路径)。少一条路径就会产生资源泄漏,销毁多次还会导致未定义行为。
- 一般来说没有办法告诉你指针是否变成了悬空指针(dangling pointers),即内存中不再存在指针所指之物。在对象销毁后指针仍指向它们就会产生悬空指针。
条款十八:对于独占资源使用std::unique_ptr
auto delInvmt = [](Investment* pInvestment) //自定义删除器
{ //(lambda表达式)
makeLogEntry(pInvestment);
delete pInvestment;
};
template<typename... Ts>
std::unique_ptr<Investment, decltype(delInvmt)> //更改后的返回类型
makeInvestment(Ts&&... params)
{
std::unique_ptr<Investment, decltype(delInvmt)> //应返回的指针
pInv(nullptr, delInvmt);
if (/*一个Stock对象应被创建*/)
{
pInv.reset(new Stock(std::forward<Ts>(params)...));
}
else if ( /*一个Bond对象应被创建*/ )
{
pInv.reset(new Bond(std::forward<Ts>(params)...));
}
else if ( /*一个RealEstate对象应被创建*/ )
{
pInv.reset(new RealEstate(std::forward<Ts>(params)...));
}
return pInv;
}
delInvmt是从makeInvestment返回的对象的自定义的删除器。所有的自定义的删除行为接受要销毁对象的原始指针,然后执行所有必要行为实现销毁操作。在上面情况中,操作包括调用makeLogEntry然后应用delete。使用lambda创建delInvmt是方便的,而且,正如稍后看到的,比编写常规的函数更有效。- 当使用自定义删除器时,删除器类型必须作为第二个类型实参传给
std::unique_ptr。在上面情况中,就是delInvmt的类型,这就是为什么makeInvestment返回类型是std::unique_ptr<Investment, decltype(delInvmt)>。(对于decltype,更多信息查看Item3) makeInvestment的基本策略是创建一个空的std::unique_ptr,然后指向一个合适类型的对象,然后返回。为了将自定义删除器delInvmt与pInv关联,我们把delInvmt作为pInv构造函数的第二个实参。- 尝试将原始指针(比如
new创建)赋值给std::unique_ptr通不过编译,因为是一种从原始指针到智能指针的隐式转换。这种隐式转换会出问题,所以C++11的智能指针禁止这个行为。这就是通过reset来让pInv接管通过new创建的对象的所有权的原因。 - 使用
new时,我们使用std::forward把传给makeInvestment的实参完美转发出去(查看Item25)。这使调用者提供的所有信息可用于正在创建的对象的构造函数。 - 自定义删除器的一个形参,类型是
Investment*,不管在makeInvestment内部创建的对象的真实类型(如Stock,Bond,或RealEstate)是什么,它最终在lambda表达式中,作为Investment*对象被删除。这意味着我们通过基类指针删除派生类实例,为此,基类Investment必须有虚析构函数
我之前说过,当使用默认删除器时(如delete),你可以合理假设std::unique_ptr对象和原始指针大小相同。当自定义删除器时,情况可能不再如此。函数指针形式的删除器,通常会使std::unique_ptr的大小从一个字(word)增加到两个。对于函数对象形式的删除器来说,变化的大小取决于函数对象中存储的状态多少,无状态函数(stateless function)对象(比如不捕获变量的lambda表达式)对大小没有影响,这意味当自定义删除器可以实现为函数或者lambda时,尽量使用lambda
工厂函数不是std::unique_ptr的唯一常见用法。作为实现Pimpl Idiom(译注:pointer to implementation,一种隐藏实际实现而减弱编译依赖性的设计思想,《Effective C++》条款31对此有过叙述)的一种机制,它更为流行。代码并不复杂,但是在某些情况下并不直观,所以这安排在Item22的专门主题中。
std::unique_ptr有两种形式,一种用于单个对象(std::unique_ptr<T>),一种用于数组(std::unique_ptr<T[]>)。结果就是,指向哪种形式没有歧义。std::unique_ptr的API设计会自动匹配你的用法,比如operator[]就是数组对象,解引用操作符(operator*和operator->)就是单个对象专有。
你应该对数组的std::unique_ptr的存在兴趣泛泛,因为std::array,std::vector,std::string这些更好用的数据容器应该取代原始数组。std::unique_ptr<T[]>有用的唯一情况是你使用类似C的API返回一个指向堆数组的原始指针,而你想接管这个数组的所有权。
条款十九:对于共享资源使用std::shared_ptr
std::shared_ptr通过引用计数(reference count)来确保它是否是最后一个指向某种资源的指针,引用计数关联资源并跟踪有多少std::shared_ptr指向该资源。std::shared_ptr构造函数递增引用计数值(注意是通常——原因参见下面),析构函数递减值,拷贝赋值运算符做前面这两个工作。(如果sp1和sp2是std::shared_ptr并且指向不同对象,赋值“sp1 = sp2;”会使sp1指向sp2指向的对象。直接效果就是sp1引用计数减一,sp2引用计数加一。)如果std::shared_ptr在计数值递减后发现引用计数值为零,没有其他std::shared_ptr指向该资源,它就会销毁资源。
引用计数暗示着性能问题:
std::shared_ptr大小是原始指针的两倍,因为它内部包含一个指向资源的原始指针,还包含一个指向资源的引用计数值的原始指针。(这种实现法并不是标准要求的,但是我(指原书作者Scott Meyers)熟悉的所有标准库都这样实现。)- 引用计数的内存必须动态分配。 概念上,引用计数与所指对象关联起来,但是实际上被指向的对象不知道这件事情(译注:不知道有一个关联到自己的计数值)。因此它们没有办法存放一个引用计数值。(一个好消息是任何对象——甚至是内置类型的——都可以由
std::shared_ptr管理。)Item21会解释使用std::make_shared创建std::shared_ptr可以避免引用计数的动态分配,但是还存在一些std::make_shared不能使用的场景,这时候引用计数就会动态分配。 - 递增递减引用计数必须是原子性的,因为多个reader、writer可能在不同的线程。比如,指向某种资源的
std::shared_ptr可能在一个线程执行析构(于是递减指向的对象的引用计数),在另一个不同的线程,std::shared_ptr指向相同的对象,但是执行的却是拷贝操作(因此递增了同一个引用计数)。原子操作通常比非原子操作要慢,所以即使引用计数通常只有一个word大小,你也应该假定读写它们是存在开销的。
类似std::unique_ptr(参见Item18),std::shared_ptr使用delete作为资源的默认销毁机制,但是它也支持自定义的删除器。这种支持有别于std::unique_ptr。对于std::unique_ptr来说,删除器类型是智能指针类型的一部分。对于std::shared_ptr则不是:
auto loggingDel = [](Widget *pw) //自定义删除器
{ //(和条款18一样)
makeLogEntry(pw);
delete pw;
};
std::unique_ptr< //删除器类型是
Widget, decltype(loggingDel) //指针类型的一部分
> upw(new Widget, loggingDel);
std::shared_ptr<Widget> //删除器类型不是
spw(new Widget, loggingDel); //指针类型的一部分std::shared_ptr的设计更为灵活。考虑有两个std::shared_ptr<Widget>,每个自带不同的删除器(比如通过lambda表达式自定义删除器):
auto customDeleter1 = [](Widget *pw) { … }; //自定义删除器,
auto customDeleter2 = [](Widget *pw) { … }; //每种类型不同
std::shared_ptr<Widget> pw1(new Widget, customDeleter1);
std::shared_ptr<Widget> pw2(new Widget, customDeleter2);因为pw1和pw2有相同的类型,所以它们都可以放到存放那个类型的对象的容器中:
std::vector<std::shared_ptr<Widget>> vpw{ pw1, pw2 };它们也能相互赋值,也可以传入一个形参为std::shared_ptr<Widget>的函数。但是自定义删除器类型不同的std::unique_ptr就不行,因为std::unique_ptr把删除器视作类型的一部分。
另一个不同于std::unique_ptr的地方是,指定自定义删除器不会改变std::shared_ptr对象的大小。不管删除器是什么,一个std::shared_ptr对象都是两个指针大小。这是个好消息,但是它应该让你隐隐约约不安。自定义删除器可以是函数对象,函数对象可以包含任意多的数据。它意味着函数对象是任意大的。std::shared_ptr怎么能引用一个任意大的删除器而不使用更多的内存?
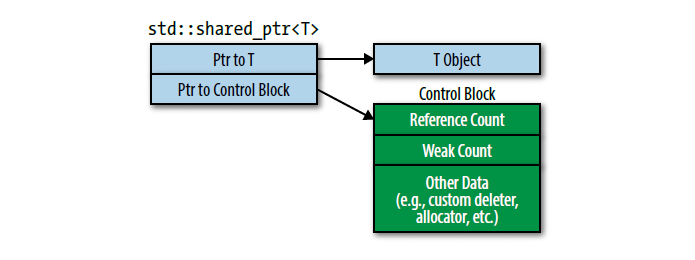
它不能。它必须使用更多的内存。然而,那部分内存不是std::shared_ptr对象的一部分。那部分在堆上面,或者std::shared_ptr创建者利用std::shared_ptr对自定义分配器的支持能力,那部分内存随便在哪都行。我前面提到了std::shared_ptr对象包含了所指对象的引用计数的指针。没错,但是有点误导人。因为引用计数是另一个更大的数据结构的一部分,那个数据结构通常叫做控制块(control block)。每个std::shared_ptr管理的对象都有个相应的控制块。控制块除了包含引用计数值外还有一个自定义删除器的拷贝,当然前提是存在自定义删除器。如果用户还指定了自定义分配器,控制块也会包含一个分配器的拷贝。控制块可能还包含一些额外的数据,正如Item21提到的,一个次级引用计数weak count,但是目前我们先忽略它。我们可以想象std::shared_ptr对象在内存中是这样:
当指向对象的std::shared_ptr一创建,对象的控制块就建立了。至少我们期望是如此。通常,对于一个创建指向对象的std::shared_ptr的函数来说不可能知道是否有其他std::shared_ptr早已指向那个对象,所以控制块的创建会遵循下面几条规则:
std::make_shared(参见Item21)总是创建一个控制块。它创建一个要指向的新对象,所以可以肯定std::make_shared调用时对象不存在其他控制块。- 当从独占指针(即
std::unique_ptr或者std::auto_ptr)上构造出std::shared_ptr时会创建控制块。独占指针没有使用控制块,所以指针指向的对象没有关联控制块。(作为构造的一部分,std::shared_ptr侵占独占指针所指向的对象的独占权,所以独占指针被设置为null) - 当从原始指针上构造出
std::shared_ptr时会创建控制块。如果你想从一个早已存在控制块的对象上创建std::shared_ptr,你将假定传递一个std::shared_ptr或者std::weak_ptr(参见Item20)作为构造函数实参,而不是原始指针。用std::shared_ptr或者std::weak_ptr作为构造函数实参创建std::shared_ptr不会创建新控制块,因为它可以依赖传递来的智能指针指向控制块。
这些规则造成的后果就是从原始指针上构造超过一个std::shared_ptr就会让你走上未定义行为的快车道,因为指向的对象有多个控制块关联。多个控制块意味着多个引用计数值,多个引用计数值意味着对象将会被销毁多次(每个引用计数一次)。那意味着像下面的代码是有问题的,很有问题,问题很大:
auto pw = new Widget; //pw是原始指针
…
std::shared_ptr<Widget> spw1(pw, loggingDel); //为*pw创建控制块
…
std::shared_ptr<Widget> spw2(pw, loggingDel); //为*pw创建第二个控制块创建原始指针pw指向动态分配的对象很糟糕,因为它完全背离了这章的建议:倾向于使用智能指针而不是原始指针。(如果你忘记了该建议的动机,请翻到本章开头)。撇开那个不说,创建pw那一行代码虽然让人厌恶,但是至少不会造成未定义程序行为。
现在,传给spw1的构造函数一个原始指针,它会为指向的对象创建一个控制块(因此有个引用计数值)。这种情况下,指向的对象是*pw(即pw指向的对象)。就其本身而言没什么问题,但是将同样的原始指针传递给spw2的构造函数会再次为*pw创建一个控制块(所以也有个引用计数值)。因此*pw有两个引用计数值,每一个最后都会变成零,然后最终导致*pw销毁两次。第二个销毁会产生未定义行为。
std::shared_ptr给我们上了两堂课。第一,避免传给std::shared_ptr构造函数原始指针。通常替代方案是使用std::make_shared(参见Item21),不过上面例子中,我们使用了自定义删除器,用std::make_shared就没办法做到。第二,如果你必须传给std::shared_ptr构造函数原始指针,直接传new出来的结果,不要传指针变量。
如果上面代码第一部分这样重写,会少了很多从原始指针上构造第二个std::shared_ptr的诱惑。相应的,创建spw2也会很自然的用spw1作为初始化参数(即用std::shared_ptr拷贝构造函数),那就没什么问题了:
std::shared_ptr<Widget> spw1(new Widget, //直接使用new的结果
loggingDel);
std::shared_ptr<Widget> spw2(spw1); //spw2使用spw1一样的控制块一个尤其令人意外的地方是使用this指针作为std::shared_ptr构造函数实参的时候可能导致创建多个控制块。
条款二十:当std::shared_ptr可能悬空时使用std::weak_ptr
自相矛盾的是,如果有一个像std::shared_ptr(见Item19)的但是不参与资源所有权共享的指针是很方便的。换句话说,是一个类似std::shared_ptr但不影响对象引用计数的指针。这种类型的智能指针必须要解决一个std::shared_ptr不存在的问题:可能指向已经销毁的对象。一个真正的智能指针应该跟踪所指对象,在悬空时知晓,悬空(dangle)就是指针指向的对象不再存在。这就是对std::weak_ptr最精确的描述。
你可能想知道什么时候该用std::weak_ptr。你可能想知道关于std::weak_ptr API的更多。它什么都好除了不太智能。std::weak_ptr不能解引用,也不能测试是否为空值。因为std::weak_ptr不是一个独立的智能指针。它是std::shared_ptr的增强。
这种关系在它创建之时就建立了。std::weak_ptr通常从std::shared_ptr上创建。当从std::shared_ptr上创建std::weak_ptr时两者指向相同的对象,但是std::weak_ptr不会影响所指对象的引用计数:
auto spw = //spw创建之后,指向的Widget的
std::make_shared<Widget>(); //引用计数(ref count,RC)为1。
//std::make_shared的信息参见条款21
…
std::weak_ptr<Widget> wpw(spw); //wpw指向与spw所指相同的Widget。RC仍为1
…
spw = nullptr; //RC变为0,Widget被销毁。
//wpw现在悬空
//悬空的std::weak_ptr被称作已经expired(过期)
if (wpw.expired()) … //如果wpw没有指向对象…但是通常你期望的是检查std::weak_ptr是否已经过期,如果没有过期则访问其指向的对象。这做起来可不是想着那么简单。因为缺少解引用操作,没有办法写这样的代码。即使有,将检查和解引用分开会引入竞态条件:在调用expired和解引用操作之间,另一个线程可能对指向这对象的std::shared_ptr重新赋值或者析构,并由此造成对象已析构。这种情况下,你的解引用将会产生未定义行为。
你需要的是一个原子操作检查std::weak_ptr是否已经过期,如果没有过期就访问所指对象。这可以通过从std::weak_ptr创建std::shared_ptr来实现,具体有两种形式可以从std::weak_ptr上创建std::shared_ptr,具体用哪种取决于std::weak_ptr过期时你希望std::shared_ptr表现出什么行为。一种形式是std::weak_ptr::lock,它返回一个std::shared_ptr,如果std::weak_ptr过期这个std::shared_ptr为空
std::shared_ptr<Widget> spw1 = wpw.lock(); //如果wpw过期,spw1就为空
auto spw2 = wpw.lock(); //同上,但是使用auto另一种形式是以std::weak_ptr为实参构造std::shared_ptr。这种情况中,如果std::weak_ptr过期,会抛出一个异常:
std::shared_ptr<Widget> spw3(wpw); //如果wpw过期,抛出std::bad_weak_ptr异常条款二十一:优先考虑使用std::make_unique和std::make_shared,而非直接使用new
std::shared_ptr<Widget> spw(new Widget);需要俩次内存分配,且中间被打断就会泄露。
更倾向于使用make函数而不是直接使用new的争论非常激烈。尽管它们在软件工程、异常安全和效率方面具有优势,但本条款的建议是,更倾向于使用make函数,而不是完全依赖于它们。这是因为有些情况下它们不能或不应该被使用。
例如,make函数都不允许指定自定义删除器(见Item18和19),但是std::unique_ptr和std::shared_ptr有构造函数这么做。
条款二十二:当使用Pimpl惯用法,请在实现文件中定义特殊成员函数
第5章 右值引用,移动语义,完美转发
条款二十三:理解std::move和std::forward
第一,不要在你希望能移动对象的时候,声明他们为const。对const对象的移动请求会悄无声息的被转化为拷贝操作。第二点,std::move不仅不移动任何东西,而且它也不保证它执行转换的对象可以被移动。关于std::move,你能确保的唯一一件事就是将它应用到一个对象上,你能够得到一个右值。
关于std::forward的故事与std::move是相似的,但是与std::move总是无条件的将它的实参为右值不同,std::forward只有在满足一定条件的情况下才执行转换。std::forward是有条件的转换。要明白什么时候它执行转换,什么时候不,想想std::forward的典型用法。最常见的情景是一个模板函数,接收一个通用引用形参,并将它传递给另外的函数。
move与forward的区别?
注意,第一,std::move只需要一个函数实参(rhs.s),而std::forward不但需要一个函数实参(rhs.s),还需要一个模板类型实参std::string。其次,我们传递给std::forward的类型应当是一个non-reference,因为惯例是传递的实参应该是一个右值(见Item28)。同样,这意味着std::move比起std::forward来说需要打更少的字,并且免去了传递一个表示我们正在传递一个右值的类型实参。同样,它根绝了我们传递错误类型的可能性(例如,std::string&可能导致数据成员s被复制而不是被移动构造)。
更重要的是,std::move的使用代表着无条件向右值的转换,而使用std::forward只对绑定了右值的引用进行到右值转换。这是两种完全不同的动作。前者是典型地为了移动操作,而后者只是传递(亦为转发)一个对象到另外一个函数,保留它原有的左值属性或右值属性。因为这些动作实在是差异太大,所以我们拥有两个不同的函数(以及函数名)来区分这些动作。
条款二十四:区分通用引用与右值引用
注意特殊情况的区分
条款二十五:对右值引用使用std::move,对通用引用使用std::forward
注意RVO的特殊情况
条款二十六:避免在通用引用上重载
使用通用引用的函数在C++中是最贪婪的函数。它们几乎可以精确匹配任何类型的实参(极少不适用的实参在Item30中介绍)。这也是把重载和通用引用组合在一块是糟糕主意的原因:通用引用的实现会匹配比开发者预期要多得多的实参类型。
条款二十七:熟悉通用引用重载的替代方法
tag dispatch的关键是存在单独一个函数(没有重载)给客户端API。这个单独的函数分发给具体的实现函数。
Comments NOTHING